


It’s already half-way into 2020 and the whole tech world is now embracing serverless computing. According to Nasdaq’s 2020 Tech Trends report, “[serverless computing] is reducing capital costs and shifting the focus to customers’ needs instead of setting up, configuring, patching and maintaining servers in the data center”.
Serverless computing can be and is being used across many technical use cases with significant gains over the traditional server-based approach. One of those use cases is the development of HTTP APIs. In pre-serverless days, developing an API included many responsibilities; from developing the actual business logic, configuring a suitable web server, managing the server deployments, securing the APIs as well as taking care of the availability and the scalability of the API throughout the day. But with the eruption of serverless technologies, most of those responsibilities are undertaken by the serverless provider and the developer has the flexibility to simply focus on the actual business logic of the APIs.
In this article, let’s first briefly look into the API development related services provided by the most popular serverless service provider, Amazon Web Services (AWS), and then discuss 3 of the most important aspects to consider when designing and deploying APIs utilizing these services.
Serverless APIs with Amazon Web Services (AWS)
In AWS, building a serverless API involves 2 services, which are AWS API Gateway and AWS Lambda. The AWS API Gateway can be used to manage the API endpoints and it completely takes care of the HTTP level request-response handling. Also, the API Gateway provides the capabilities to manage API versions with stages, API security features with several types of authorization mechanisms, and also different types of API request throttling controls.
Then AWS Lambda functions can be utilized to handle the business logic of these API calls received by the API Gateway endpoints. Each API Gateway endpoint can be integrated with Lambda as a trigger so that when a request is received by a particular endpoint, the configured Lambda function will be invoked with that request details. Then the Lambda function can process the request and return back a suitable response to the API Gateway. The API Gateway will generate the HTTP response based on this and send it back to the client who invoked the API.
Now let’s see 3 of the most important aspects to be aware of when you are building APIs with these services.
1. Mapping API endpoints to Lambda functions
One of the most critical design decisions to take when a serverless API is designed is, how the API endpoints can be mapped to Lambda functions for processing the requests. Let’s look into 2 of the widely used approaches for mapping API endpoints to Lambda functions.
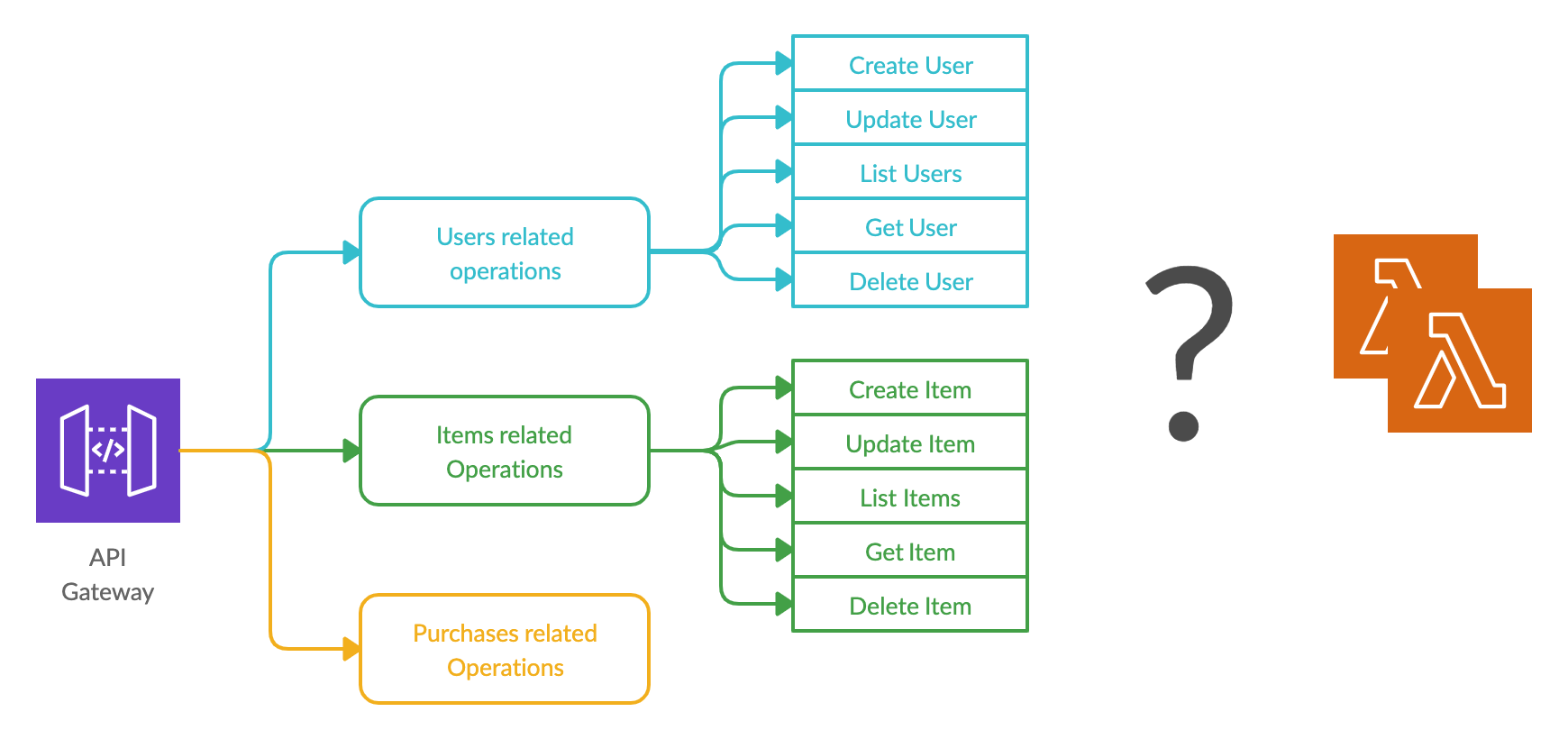
We are going to consider an API of an online retail store to discuss these approaches. This API will be used to manage resources such as users, retail items, and purchases, while each of these resources will have multiple endpoints/methods for different operations on them.
1.1. Lambda per Resource approach
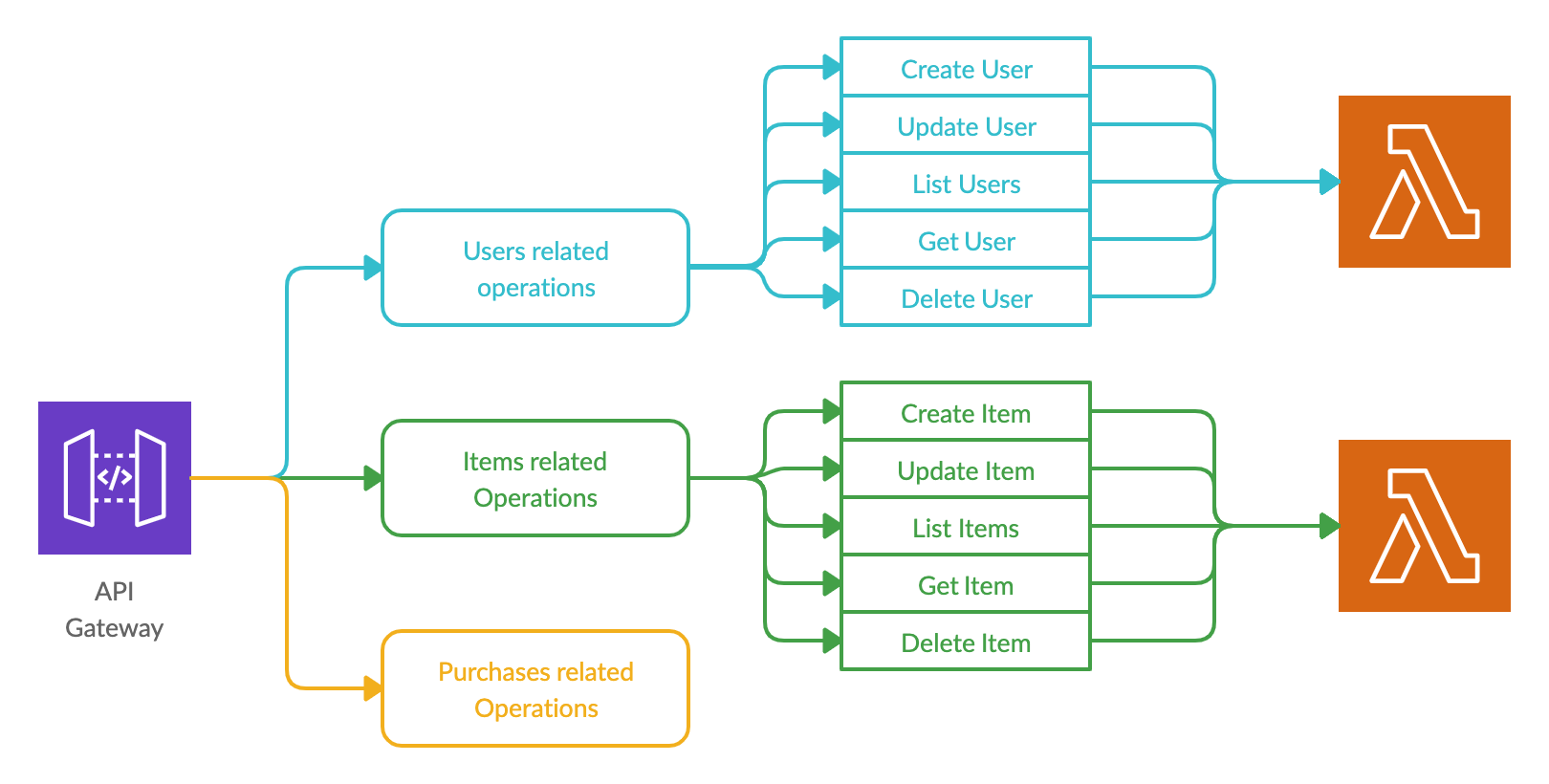
In this approach, all the requests to a particular resource will be directed to the same Lambda function. Then within the Lambda function, these requests will be re-routed to different processing branches based on the requested operation. For example, a request for creating a new user and a request for retrieving details of an existing user will invoke the same Lambda function. A request for updating a listed item and a request to get a list of available items will invoke another Lambda function. Then that invoked Lambda code will identify the requested operation and process it accordingly. A library such as AWS Serverless Express can be utilized to perform this internal routing easily and efficiently.
Advantages
- Less number of Lambda functions to be managed
- Easy to reuse resource-specific common code, libraries & utilities between operations
- Resource-wide modifications require updating only one Lambda function
Disadvantages
- An update to a single operation may impact all the operations within the same Lambda function
- 2-level routing (first at the API Gateway level, and then at the internal routing level) can introduce an overhead
- The same lambda function should be granted to have all the execution permissions requires for each operation, which can be a security risk
- Not possible to fine-tune Lambda function parameters such as memory, timeout and concurrent executions based on the operation
- If there are operation-specific libraries, they all will be loaded irrespective of the operation to be executed, which can extend the cold-start time of the Lambda
1.2. Lambda per Operation approach
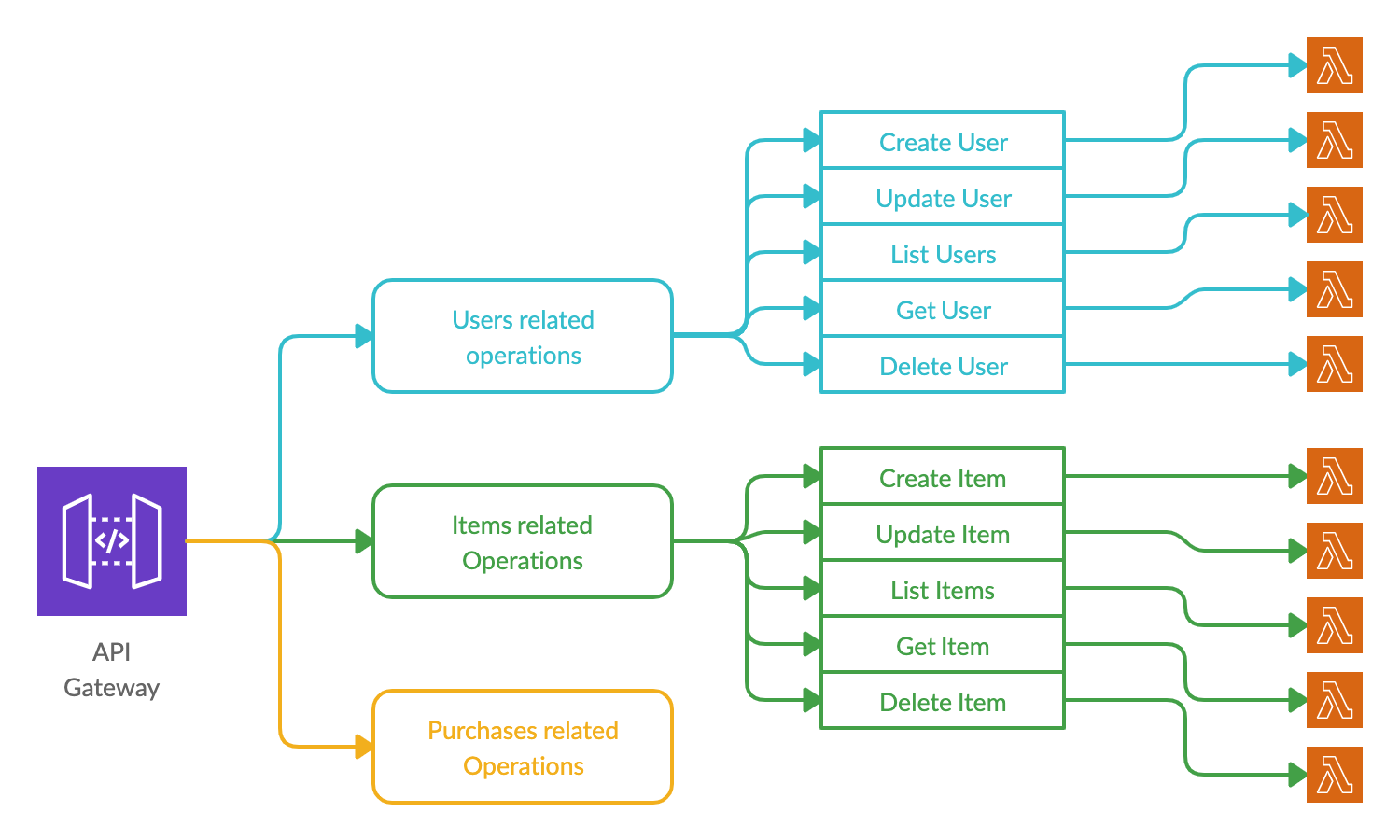
In this approach, there is a separate Lambda function of each operation of each resource. For example, a request for creating a new user will be processed by one Lambda function while a request for retrieving details of an existing user will be processed by another. In this case, there is no need for an internal routing mechanism and the routing is completely performed at the API Gateway level.
Advantages
- Each operation can be independently updated and tested without impacting other operations
- Lambda function should be only granted the minimal execution permissions for the specific operation
- Lambda function parameters such as memory, timeout and concurrent executions can be fine-tuned based on operation
- Each Lambda function requires to load only the libraries required for its intended operation
Disadvantages
- A large number of Lambda function to be managed
- Resource-wide modifications require updating several Lambda functions
- Reusing resource-specific common code, libraries & utilities between operations will require additional measures such as publishing them as Node modules or Lambda layers.
As mentioned above, both these approaches have their own advantages and disadvantages from both performance point-of-view and deployment management point-of-view. Therefore it is our responsibility to choose the appropriate approach based on our requirements and use case.
2. Regular Lambda Integration vs. Lambda Proxy Integration
AWS API Gateway provides 2 main ways to integrate its endpoints with Lambda functions. Based on what information is required by the Lambda function for processing the request, we need to select one of these integration methods for each of our API Gateway – Lambda integrations.
2.1. Regular Lambda Integration
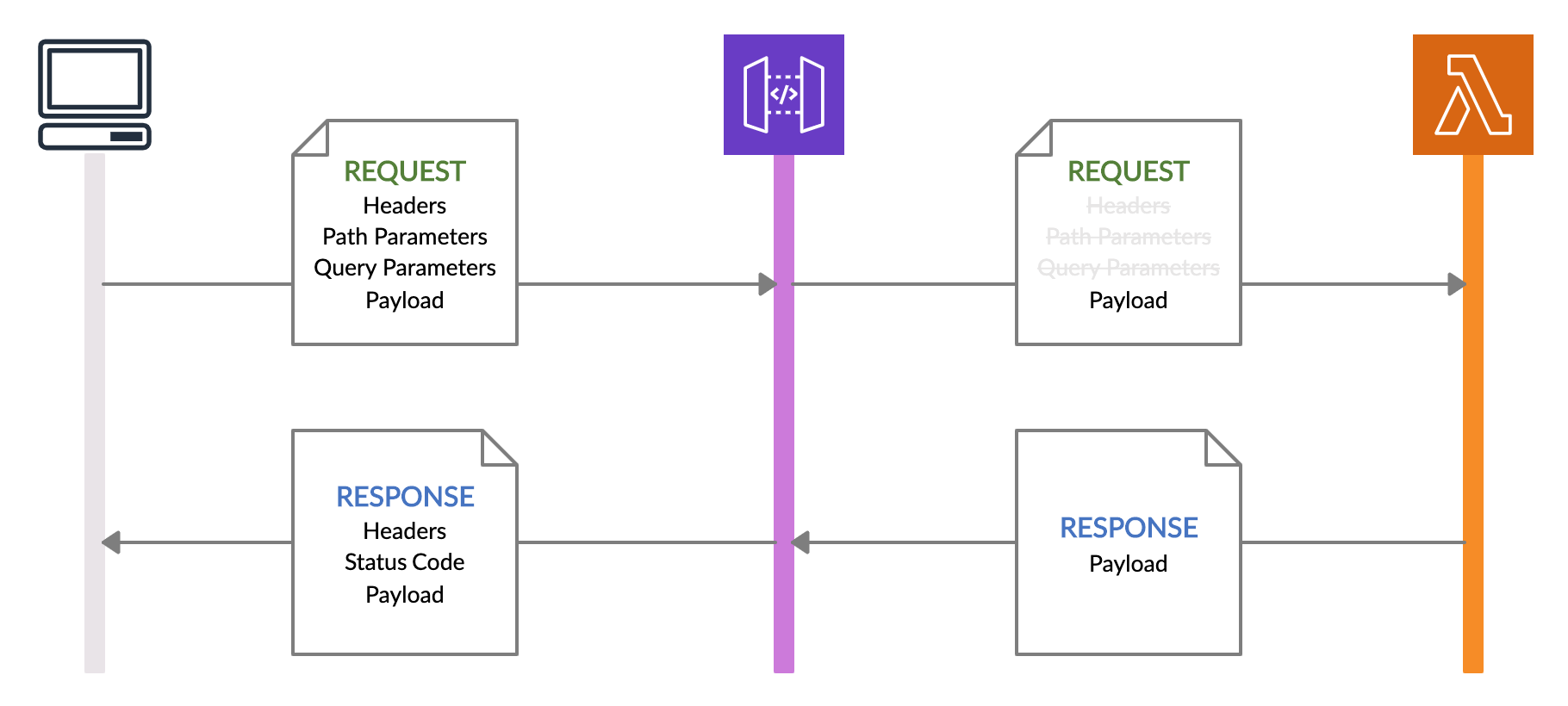
The first method is the regular Lambda integration method, in which the API gateway forwards only the request payload to the Lambda function as its trigger event. Then the Lambda function also is required to send back only the response payload to the API Gateway. In cases where the Lambda function requires only the request payload to process the request, we can use this integration method.
2.2. Lambda Proxy Integration
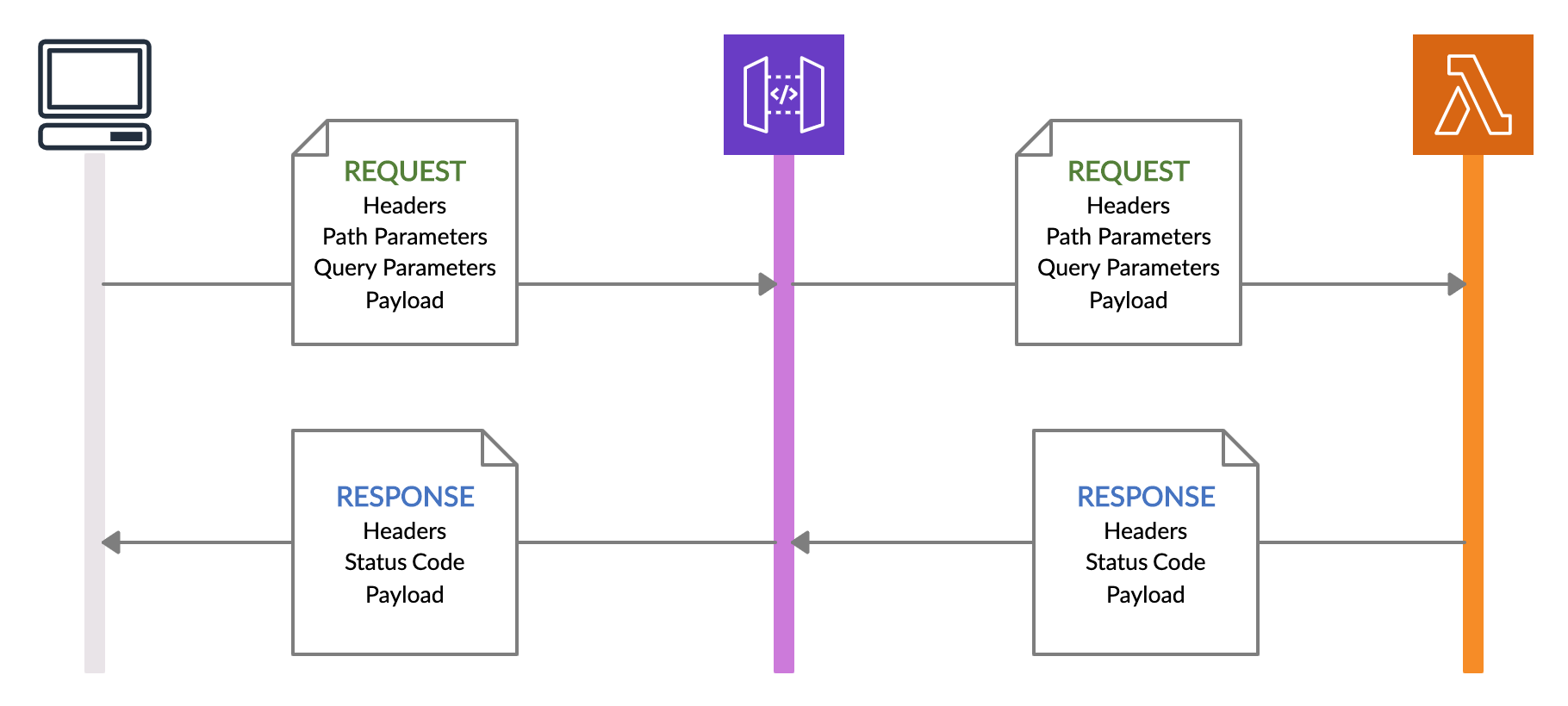
The second method is Lambda Proxy integration, in which the API gateway forwards the complete HTTP request details including,
- request headers
- path parameters
- query string parameters
- resource details
- stage information
- and, of course, the payload
to the Lambda function. Then the Lambda function is also responsible for sending back the response headers and the status code in addition to the response payload. In cases where the Lambda function requires information such as header values and path/query parameters for the processing, we can use this integration method.
3. API authentication
Access control and authentication is another key factor to be considered when designing not only serverless APIs, but also any type of API. Therefore AWS API Gateway also provides the following mechanisms for authentication and authorization.
- Resource policies
- Standard AWS IAM roles and policies
- IAM tags
- Endpoint Policies for Interface VPC Endpoints
- Lambda authorizers
- Amazon Cognito user pools
From these, the last 2 mechanisms are widely used with the serverless APIs. Therefore let’s briefly see what those 2 mechanisms offer.
3.1. Amazon Cognito user pools
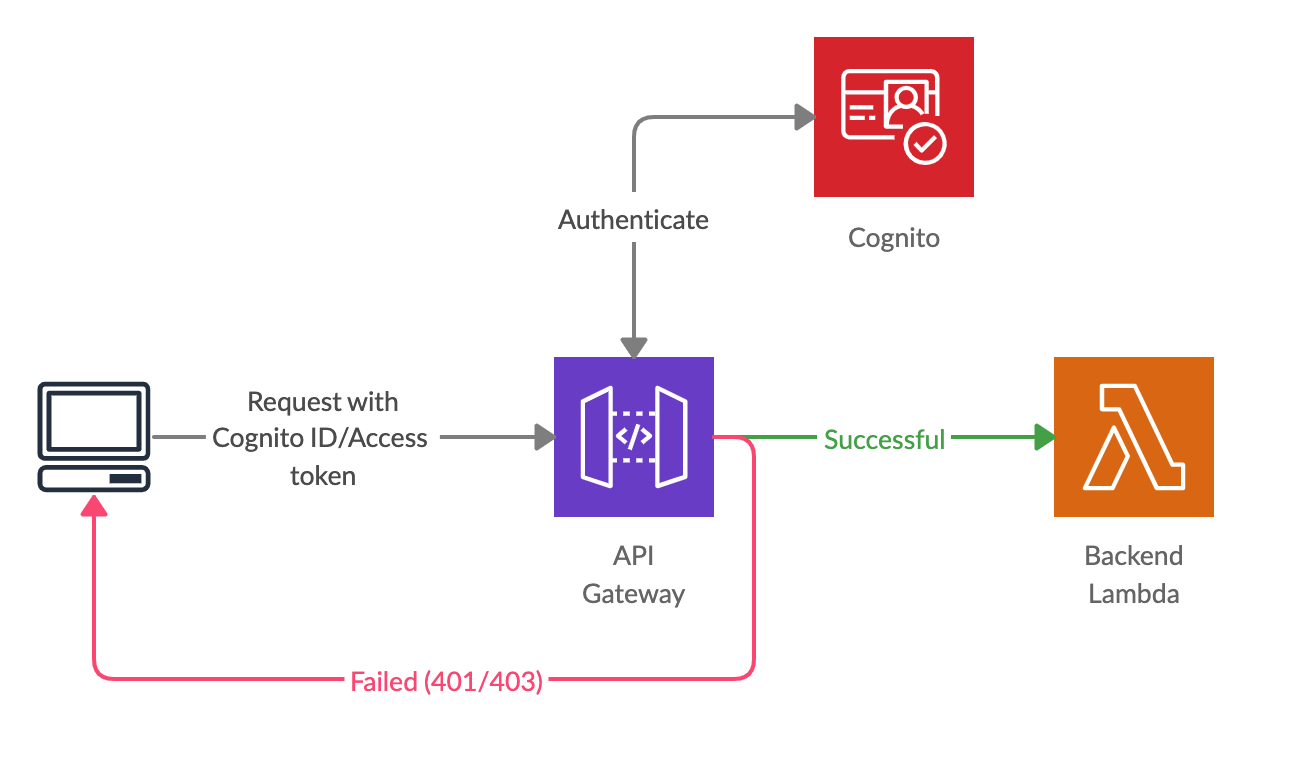
If we are using AWS Cognito service for user management, this mechanism is the most convenient and efficient way to authenticate API requests. When this mechanism is used, we have to create an API Gateway authorizer specifying which Cognito user pool(s) should be used to grant access to this API. Then the client has to send a valid Cognito ID token (or Access token, depending on the configuration) as an HTTP header of the request. Typically, this should be sent as the Authorization header, but it is possible to configure the authorizer to use any other custom header as well.
Once such a request is received by the API Gateway, it uses that token to authenticate the user with the Cognito user pool. If the authentication was successful, the relevant Lambda function will be invoked as usual. If Lambda Proxy integration is used, the user details decoded from the token will also be included within the Lambda event, so it is very convenient and useful to perform user-specific operations. In case the authentication fails, API Gateway itself sends back a “401 Unauthorized” response, even without invoking the Lambda function.
3.2. Lambda authorizers
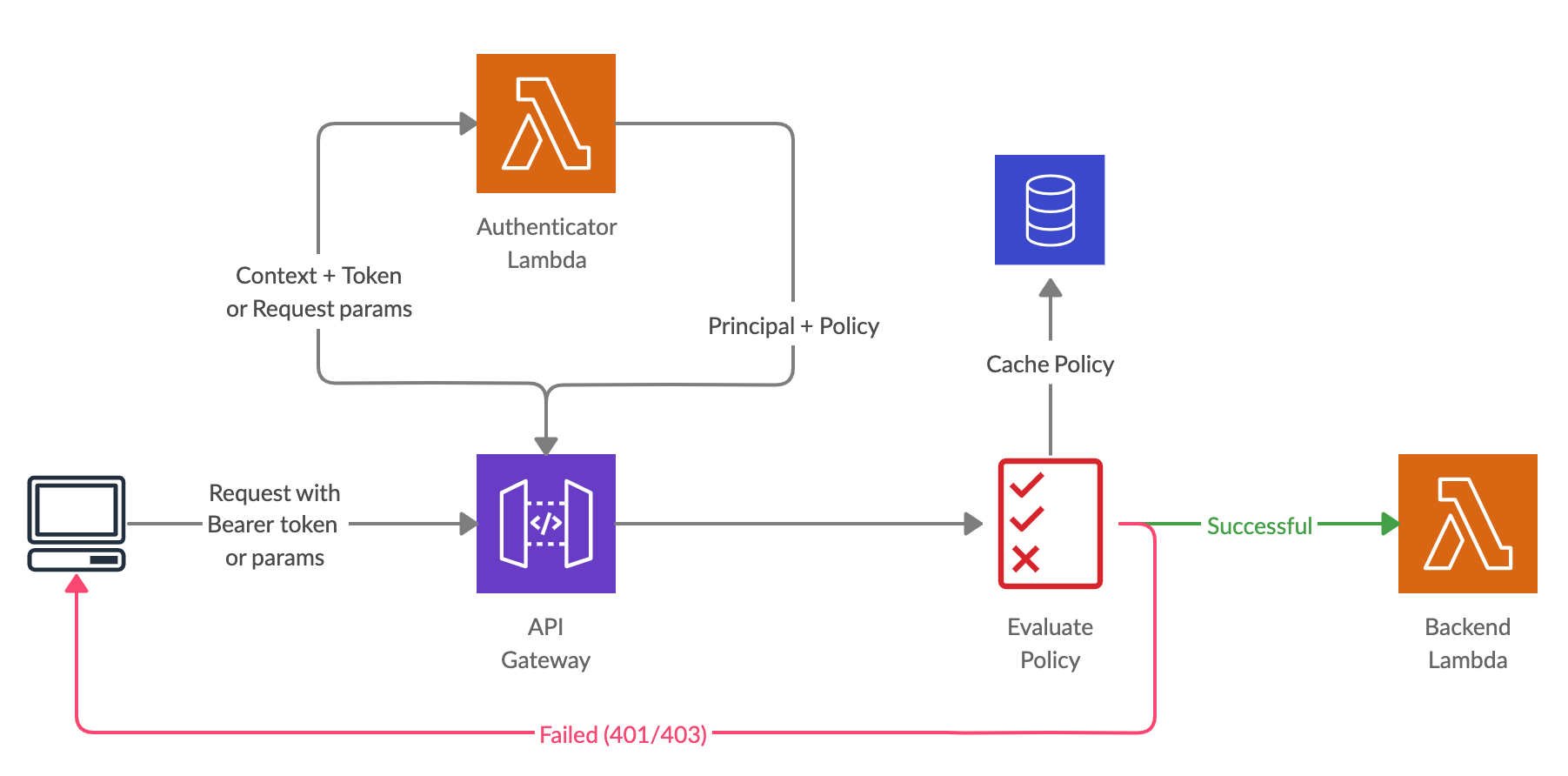
In this mechanism, we need to set up a separate authenticator Lambda function and create an API Gateway authorizer pointing to that. There are 2 types of Lambda authorizers.
- Token-based Lambda authorizer (TOKEN authorizer)
This type of authorizer receives the caller’s identity in a bearer token, such as a JSON Web Token (JWT) or an OAuth token. - Request parameter-based Lambda authorizer (REQUEST authorizer)
This type of authorizer receives the caller’s identity as a combination of headers, query string parameters, stage variables, and context variables.
Once a request is received by the API Gateway, it first invokes that authorizer Lambda function with the request details. Then the Lambda authorizer authenticates the caller by using a mechanism such as,
- calling out to an OAuth provider to get an OAuth access token
- calling out to a SAML provider to get a SAML assertion
- generating an IAM policy based on the request parameter values
- retrieving credentials from a database
If the authentication succeeds, the Lambda function should grant access by returning an output object containing at least an IAM policy and a principal identifier.
Then the API Gateway evaluates the policy, and if access is allowed, the actual backend Lambda function will be invoked next. If caching is enabled in the authorizer settings, API Gateway also caches the policy so that the Lambda authorizer function doesn’t need to be invoked again. In case the authentication failed, API Gateway returns a suitable HTTP status code, such as 403 ACCESS_DENIED.
So as discussed above, these are 3 of the most important aspects to be considered when designing a serverless API. If we can choose or configure these appropriately, it will make managing and maintaining the APIs more efficient and convenient.


